ResNet
As the number of layers in a plain net increases, the training accuracy decreases. This is attributed to the degradation problem. This might be caused due to exponentially low convergence rates of deeper networks (I think).

Adding a skip step allows preconditioning the problem. Having an identity mapping (I think it means just carrying over the input x without any modification) adds no extra parameter, and aids this preconditioning. In back propagation, the gradient just distributes equally among all its children so the layers between the skip step learn to produce H(x)-x effectively and gradient flows back via skip step to input step. I think this causes a faster convergence. Another way to think, the net is effectively translating the identity and the layers in between are just computing a delta over this x.
H(x) = F(x) + x;
F(x) is a small delta over x that layers are learning to set up.
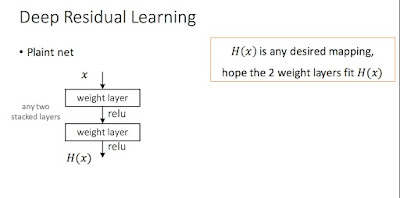


The difference between plain net and resnet is that the layers are now learning for parameters so as to produce H(x)-x rather than H(x) for the same desired output. It has been experimentally proven that a deeper resnet converges successfully and has lower training error rate compared to its counter plain net. As for a shallow network, the accuracy of resnet is similar to plain net although it converges faster.
-uses batch normalization after every conv and before relu activation.
-does not use drop out because BN paper says u dont need drop out when using BN
-learning rate 0.1, divided by 10 when the validation error plateaus.
Summary:
- Using plain nets like VGGNet, AlexNet, etc till now.
- It is observed that increasing number of layers in these plainNets increases training error as opposed to obvious intuition.
- ResNet decreases the error consistently.
- Even though it has 152 layers, its faster than VGGNet
- The good thing about this network is in back prop the gradient just distributes evenly into its children, so it uniformly flows back in the skip step and the layers in between learn to adjust accordingly.
- This is very similar to RNN/LSTM where we are using past knowledge to affect decisions made in the future.
Extra Notes:


Sources and References:
1. http://arxiv.org/pdf/1512.03385v1.pdf
2. https://www.youtube.com/watch?v=LxfUGhug-iQ&index=7&list=PLkt2uSq6rBVctENoVBg1TpCC7OQi31AlC
3. https://www.youtube.com/watch?v=1PGLj-uKT1w
Left to cover:
1. code analysis
2. Math of forward and back prop
3. bottleneck architecture
4. transfer from lesser to high dimension on skip step.
As the number of layers in a plain net increases, the training accuracy decreases. This is attributed to the degradation problem. This might be caused due to exponentially low convergence rates of deeper networks (I think).

Adding a skip step allows preconditioning the problem. Having an identity mapping (I think it means just carrying over the input x without any modification) adds no extra parameter, and aids this preconditioning. In back propagation, the gradient just distributes equally among all its children so the layers between the skip step learn to produce H(x)-x effectively and gradient flows back via skip step to input step. I think this causes a faster convergence. Another way to think, the net is effectively translating the identity and the layers in between are just computing a delta over this x.
H(x) = F(x) + x;
F(x) is a small delta over x that layers are learning to set up.



-uses batch normalization after every conv and before relu activation.
-does not use drop out because BN paper says u dont need drop out when using BN
-learning rate 0.1, divided by 10 when the validation error plateaus.
Summary:
- Using plain nets like VGGNet, AlexNet, etc till now.
- It is observed that increasing number of layers in these plainNets increases training error as opposed to obvious intuition.
- ResNet decreases the error consistently.
- Even though it has 152 layers, its faster than VGGNet
- The good thing about this network is in back prop the gradient just distributes evenly into its children, so it uniformly flows back in the skip step and the layers in between learn to adjust accordingly.
- This is very similar to RNN/LSTM where we are using past knowledge to affect decisions made in the future.
Extra Notes:


Sources and References:
1. http://arxiv.org/pdf/1512.03385v1.pdf
2. https://www.youtube.com/watch?v=LxfUGhug-iQ&index=7&list=PLkt2uSq6rBVctENoVBg1TpCC7OQi31AlC
3. https://www.youtube.com/watch?v=1PGLj-uKT1w
Left to cover:
1. code analysis
2. Math of forward and back prop
3. bottleneck architecture
4. transfer from lesser to high dimension on skip step.
No comments:
Post a Comment